

O tom, že a ako používame GitLab pipelines už viete. A hoci sa nám vďaka nim darí vyvíjať bezpečnejšie a efektívnejšie, ich používanie nie je bez dane. Platíme ju v podobe zdrojov potrebných na ich fungovanie. A keď vyvíjame veľa a naše pipelines “horia”, je tých zdrojov naozaj veľa. Aby sme ušetrili, čo sa dá, siahli sme v AWS po autoškálovaní.
Aby sme ale nepredbiehali, v súčasnosti používame na projekte Crossuite dva prístupy k autoškálovaniu: docker-machine aj službu Auto scaling groups (ASG) od AWS.
Fungovanie docker-machine
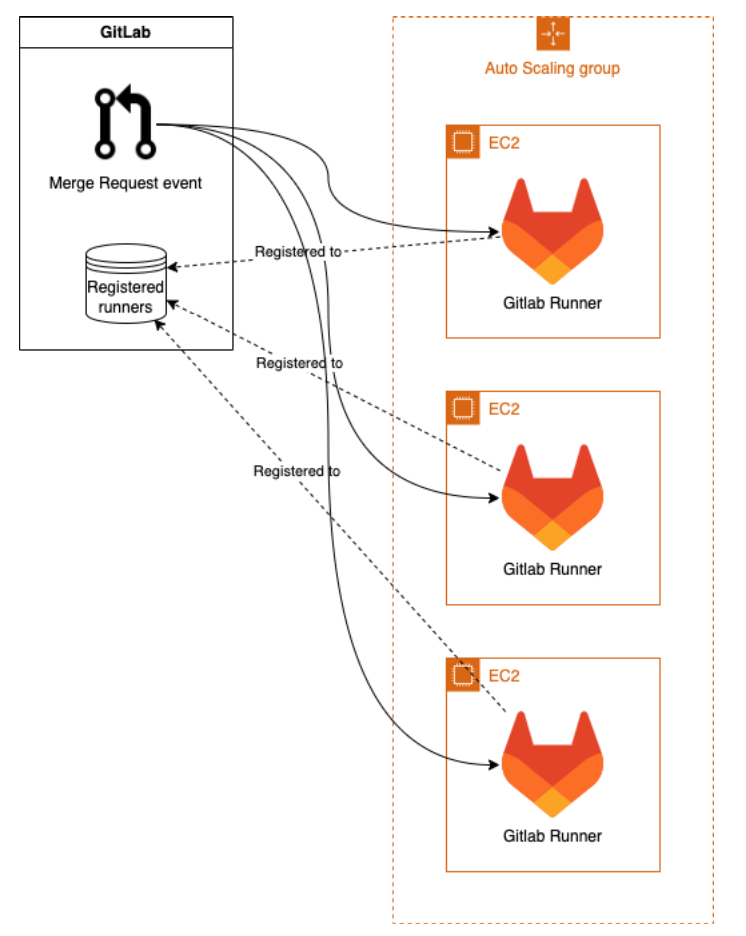
Pri tomto riešení je v GitLab-e zaregistrovaný len jeden runner, ktorý spravuje vytváranie/ukončovanie všetkých ostatných inštancií. Runnery sú vytvárané na základe aktuálneho dopytu, takže ak je v poradí 5 úloh, vytvorí sa na pokrytie tejto potreby 5 strojov. Jeden stroj (manažér GitLab runnerov) musí byť aktívny 24/7, no z hľadiska výkonu nemusí byť veľmi silný, pretože len udržuje spojenie s gitlabom a manažuje vytváranie/terminovanie inštancií.
Takéto riešenie autoškálovania je odporúčané priamo GitLabom. Dôvodom je najmä jednoduché nastavenie a nonstop bežiaci manažérsky stroj, ktorý môže byť prevádzkovaný pomerne lacno. Prináša však so sebou aj niekoľko nevýhod. Napríklad mu čoskoro končí podpora a jeden stroj dokáže riešiť len jednu úlohu.
Docker-machine je v tom, čo robí, veľmi efektívny. Niektoré úlohy v projekte si však vyžadujú iné behové prostredie, ako docker, pretože by v ňom bežali príliš dlho. A práve kvôli nim sme sa začali začiatkom roka aktívne venovať prístupu číslo 2.
Fungovanie Amazon Scale Group (ASG)
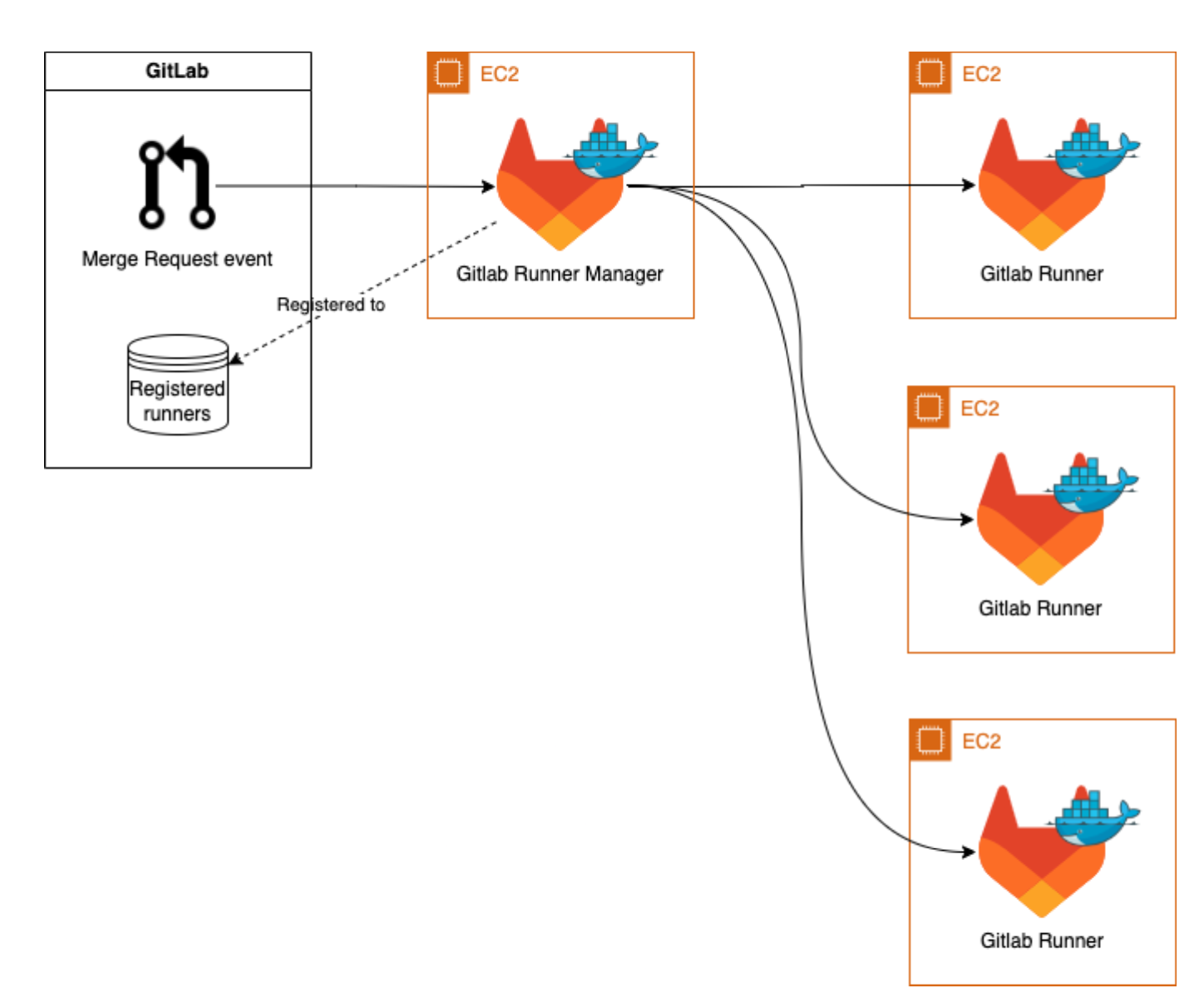
Pri tomto prístupe je každý runner zaregistrovaný v GitLabe. Runnery sú pritom vytvárané na základe aktuálneho využitia CPU v celej skupine. Ak je dosiahnutá určitá hraničná hodnota, vytvárajú sa nové stroje. Nevýhodou je, že jeden plnohodnotný výkonný stroj musí byť aktívny 24/7. Zároveň však jeden stroj dokáže vykonávať aj viacero úloh a navyše je využitie zdrojov možné efektívne spravovať pomocou služieb CloudFormation a CloudWatch.
Naše hraničné hodnoty
Obe služby sú poskytované AWS-kom práve preto, aby si používateľ mohol efektívne zautomatizovať proces vytvárania a správy infraštruktúry v cloude. S využitím šablón CloudFormation je možné definovať požadované prostriedky (ako EC2 inštancie, databázové inštancie, sieťové komponenty, úložisko atď.) a ich vzájomné vzťahy.
CloudWatch, na druhej strane, umožňuje sledovať a zhromažďovať metriky, logy a udalosti z rôznych služieb v rámci AWS. Vďaka tomu môžete nastaviť hraničné hodnoty pre určité procesy aj akcie, ktoré sa majú pri dosiahnutí týchto hodnôt vykonať.
My máme nastavené dva CloudWatch alarmy, ktoré zohľadňujú aktuálne využitie CPU na všetkých inštanciách.
- Ak využitie prekročí 15 %, vytvárajú sa nové stroje.
- Ak je využitie nižšie ako 5 %, spúšťa sa program na ukončenie. Výstup toho programu určí, ktoré inštancie sa môžu terminovať.
Ktoré typy inštancií si vybrať?
Termín „inštančný typ“ znamená určitú konfiguráciu virtuálnych inštancií – kombináciu počtu CPU a množstva operačnej pamäte (RAM). Každý typ inštancie (t3a, m5a, m5, t3 a veľa ďalších) má svoje vlastné špecifikácie a cenu za každú minútu ich používania. Je teda pomerne náročné vybrať ten, ktorý bude pre projekt najlepší. V Crossuite máme v rámci používania služieb Amazon-u predplatený čas na stroje typu m5 a t3a. Ako najjednoduchší spôsob porovnania som zvolil jednoduchý test – opakovane spustil určitú vybranú úlohu s rôznymi konfiguráciami a urobil si porovnanie.
| Inštancia | CPU | RAM | Výsledný čas |
| m5.xlarge | 4 | 16 | 15m 51s |
| m5.2xlarge | 8 | 32 | 15m 7s |
| m5.8xlarge | 32 | 128 | 15m 16s |
| m5a.xlarge | 2 | 8 | >24m 4s |
| m5a.xlarge | 4 | 16 | 17m 17s |
| t3a.large | 2 | 8 | >94m 13s |
| t3a.xlarge | 4 | 16 | 18m 43s |
Najvýkonnejšia, alebo aspoň tá s najväčším potenciálom na výkon, je samozrejme m5.8xlarge, pretože má najviac CPU a RAM. Ako ale test ukázal, jeho výsledný čas je približne rovnaký, ako pri m5.xlarge. V tomto konkrétnom prípade sa teda ukázalo, že úlohy potrebujú minimálne 4 CPU a zároveň nevedia utilizovať viac ako 8GB RAM. Nasadili sme teda m5a.xlarge, ktorá nám poskytuje dostatočný pomer ceny a výkonu. Upozorňujem ale, že takýto test je dobré si urobiť pre každý job osobitne, pretože môže mať vždy odlišné nároky a teda aj inú ideálnu inštanciu.
Celkovo hodnotíme ASG od jeho nasadenia v marci 2023 ako pozitívny krok vpred. Umožnil nám totiž autoškálovanie takých úloh, ktoré docker-machine vyriešiť jednoducho nedokázal. Stále však musíme kombinovať oba prístupy, aby sme dosiahli optimálne výsledky.



