

V prvej časti série článkov s názvom Monitoring aplikácií v kocke ste sa dozvedeli o prezentačnom nástroji, ktorý zobrazuje a analyzuje dáta nevyhnutné pre monitoring našej webovej aplikácie. V tomto pokračovaní si upresníme, ako automatizujeme sledovanie, aby sme minimalizovali predvídateľné chyby a predišli tak možnému zlyhaniu aplikácie.
Cieľom nášho monitoringu je:
- Centralizovať záznamy pracovného zaťaženia servera aj klienta – Na správu týchto dát používame nástroje Prometheus a Cloudwatch.
- Získané záznamy detailne sledovať – Vizualizáciu nám na základe dát z prvého cieľa umožňuje Grafana.
- Zabezpečiť možnosť automatizácie procesov – Medzi nástroje automatizácie jednoduchého monitorovania patrí práve alerting.
Čo je to Grafana alerting a ako ho nastaviť?
V predošlom článku sme definovali najdôležitejšie aspekty monitorovania výkonu, zaťaženia, procesov, pamäte a disku. Dáta z týchto monitorovaní sú dostupné na základe spomínaného Promethea, ktorý je spolu s Cloudwatch pre alerting kľučovým.
V krátkosti:
- Prometheus: Open-source systém, ktorý používa pull model na zber metrík. To znamená, že server Prometheus pravidelne volá koncové body v sledovaných službách a získava od nich metriky.
- CloudWatch: Služba spoločnosti Amazon, ktorá používa push model (i keď podporuje pre niektoré služby aj pull). Služby a aplikácie posielajú svoje metriky do CloudWatch a na základe dát z týchto zdrojov následne vznikajú vizualizácie.
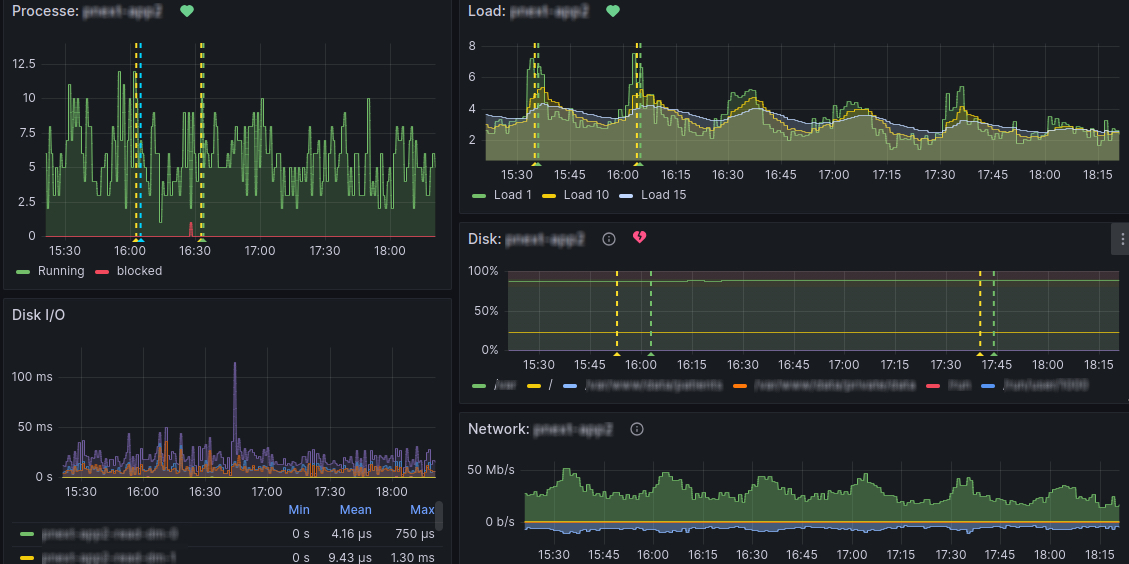
Tieto služby zasielajú svoje dáta do Grafany, ktorá ich vizualizuje. Výsledok vyzerá asi takto:

A čo znamenajú dve prerušované čiary? Ide o súčasť automatického monitoringu, ktorý je možné nastaviť nasledovne:
- V Grafane si nadefinujete Zdroj dát a spracujete si ich do podoby, ktorú potrebujete.
- Následne je dáta potrebné prečistiť, prípadne ich upraviť. Hodnoty NaN alebo NULL sa obyčajne vynechávajú. Je však potrebné zvážiť, či tieto hodnoty nie sú potrebné pre správne vyhodnotenie vašich podmienok a či ich odstránenie nespôsobí nevyžiadané ignorovanie potenciálnej chyby.
- Nakoniec určíte konkrétne podmienky nad výstupnou hodnotou, kedy upozornenie nadobudne jeden z nasledujúcich stavov:
- Normal: Bez rizík.
- Pending: Prebieha pravidelná kontrola podmienok a v prípade, že je jedna z nich splnená, sa upozornenie presunie do stavu Firing.
- Firing: Upozorní správcov, a prípadne aj klienta, o potencionálnom probléme.
Je veľmi dôležité určovať podmienky automatického monitoringu správne, aby prichádzalo čo najmenej falošných upozornení (alertov), ktoré môžu prekryť tie naozaj dôležité. V prípade častých opakovaných upozornení či falošných “poplachov” sa môžu alerty začať považovať za nedôveryhodné. Následne hrozí, že ich bude správca ignorovať, a v konečnom dôsledku tak stratia svoj pôvodný zmysel. Proces definovania týchto podmienok teda väčšinou nie je jednorázový, ale dlhodobý, aby sa v ňom vyladili všetky detaily.
U nás na Crossuite máme momentálne upozornenia rozdelené do 3 rôznych stavov:
- Warning signalizuje potenciálny problém. Používateľ môže toto upozornenie nastaviť podľa rôznych kritérií či prahových hodnôt. Nám sa Warning zobrazuje vtedy, keď sú vrátené a upravené dáta pred hranicou kritickosti, ktorú sme si vopred stanovili. Ak by tento potenicálny problém nebol riešený, mohol by v blízkej budúcnosti spôsobiť výpadok webovej aplikácie.
- Critical je issue, ktorá bola v minulosti hlásená ako Warning, ale nebola vyriešená, alebo issue spôsobená náhlou chybou. Oba typy spôsobujú potencionálny blokujúci aspekt pre používateľa a je potrebné ich okamžite riešiť.
- Business alerts sú upozornenia odchytené priamo na základe interakcie používateľa.
Príklad: Nastavenie upozornenia – míňajúci sa priestor na disku
Jeden z veľmi dôležitých alertov je využitie disku. Ak dôjde disk, môže to mať rôzne následky, ako napríklad stratu dát, výpadok služieb alebo výkonnostné problémy. Keďže žiadny z týchto následkov nie je pre koncového používateľa prijateľný, využitie disku, samozrejme spolu s mnohými ďalšími metrikami, dôkladne sledujeme.
Na nasledujúcom obrázku som vystrihol zopár upozornení z nášho automatického monitoringu. Ako je vidieť, Disk usage nie je bežný problém, keďže aj u nás je práve tento alert v stave Firing.

Ako si takýto alert nastaviť?
Data source pre alerty definujeme pomocou dopytovacieho jazyka pre Prometheus:

Čo tento príkaz robí? Laicky ho môžeme preložiť takto: „Povedz mi, koľko dostupného miesta v gigabajtoch je v každom súborovom systéme patriacom skupine ‚bart.sk‘, ale neber do úvahy tie, ktoré:
- sú na určitých zariadeniach,
- majú určité typy súborových systémov,
- sú pripojené na určitých miestach.
Pre jednoduchší prehľad ešte zaokrúhli hodnoty na tisíciny gigabajtu.“
Vysvetlenie konkrétnych metrík:
- node_filesystem_avail_bytes: Metrika obsahuje počet bajtov, ktoré sú dostupné na súborovom systéme.
- {group=“bart.sk“, …}: Filtre, ktoré určujú, ktoré súborové systémy by mali byť zahrnuté alebo vylúčené z výsledkov. Napríklad group=“bart.sk“ znamená, že sa pozeráme iba na súborové systémy, ktoré patria do skupiny „bart.sk“.
- device!~“/dev/mapper/vg_pnapi1-opt“ a podobné filtre začínajúce na device!~ definujú zahrnutie/vylúčenie určitých zariadení (disky alebo partície) určené reťazcom po !~.
- mountpoint !~ „/run.*“ a ďalšie mountpoint filtre označujú, že výsledky by nemali obsahovať určité pripojené body (miesta, kde sú disky prístupné v súborovom systéme) na základe vzoru alebo presnej cesty.
- Fstype!~“tmpfs“ určuje zahrnutie/vylúčenie súborových systémov typu „tmpfs“, čo sú dočasné súborové systémy uchovávané v pamäti RAM.
- mountpoint!=“/var/www/data/private-aws“ a ďalšie označujú zahrnutie/vylúčenie špecificky pripojených body z výsledkov.
- / (1024 * 1024 * 1024): Táto časť vzorca prevádza hodnotu z bajtov na gigabajty, pretože 1024 bajtov je jeden kilobajt, 1024 kilobajtov je jeden megabajt, a 1024 megabajtov je jeden gigabajt.
- ,0.001): Táto časť zaokrúhľuje výslednú hodnotu na tisíciny gigabajtu, aby boli hodnoty prehľadnejšie.
Dopyt nám následne zobrazí dáta v rovnakom alebo podobnom formáte, ako sme si zadefinovali pre každý súborový systém:

V ďalšom kroku, ak je to potrebné, môžeme tieto dáta očistiť od nenumerických, nedefinovaných či nulových hodnôt.

Potom definujeme podmienky vyhodnotenia, na základe ktorých sa bude tento alert priraďovať do definovaných stavov (warning, critical, business). Voľné miesto sme si zadefinovali pomocou expression, ktorá nám vráti hodnotu v percentách:
${reduced_filesystem_available_size} / ${reduced_filesystem_size} *100

V tomto prípade máme nastavené 2 podmienky:
Warning podmienka:
- Ak je hodnota menšia ako 15%, alert sa dostáva do stavu PENDING.
- Ak tento stav pretrváva dlhšie, ako definovaný čas T, potom sa alert dostane do stavu WARNING.
Critical podmienka
- Ak je hodnota menšia ako 10%, alert sa dostáva do stavu PENDING.
- Ak tento stav pretrváva dlhšie, ako definovaný čas T, potom sa alert dostane do stavu CRITICAL.
V tomto prípade je Critical podmienka vždy nadradená Warning podmienke.
Výsledný alert je následne odoslaný do priestoru zadefinovaného v rámci nastavení Grafany pomocou Webhook-u. U nás to je Google Chat.
Samotná forma a štruktúra upozornenia je definovaná pomocou templatovacieho jazyka:

Následne je možné pomocou Annotations a Variables definovať pre šablónu jednotlivé hodnoty:

Konkrétne upozornenie na nedostatok diskového priestoru potom vyzerá nasledovne:

A čo bude ďalej?
Každý alert by mal byť samozrejme nalinkovaný na nejakú grafickú vizualizáciu, vďaka ktorej je možné problém bližšie preskúmať. Tu sa dostávame k otázke z predchádzajúceho článku – čo sú vlastne tie bodkované čiary v grafoch? Ide o presné body, kde alert identifikoval problém. Takto vieme zistiť, čo situácii predchádzalo a definovať podmienky, ktoré k nej viedli. Graf, v ktorom to má alert identifikovať, sa určuje pomocou Summary and Annotations s položkami Dashboard UID a Panel ID.
Sme na konci druhého pokračovania série Monitoring v kocke a pozornému čitateľovi určite neušlo, že som nevysvetlil, na čo slúžia naše Business alerty. Nebojte sa, všetko o nich, aj to, ako súvisia s Loki logs, sa dozviete v ďalšej časti. Tak dočítania :)



