

You already know that we use GitLab pipelines and how we use them. And although we can develop more securely and efficiently, their use is not tax-free. We pay for it in the form of resources necessary for their operation. And when we develop a lot and our pipelines are really “on fire”, that needs a lot of those resources. In order to save as much as possible, we decided on auto-scaling in AWS.
However, let’s not get ahead of ourselves. We currently use two approaches to auto-scaling on the Crossuite project: docker-machine and Auto scaling groups (ASG) service from AWS.
Docker-machine functioning
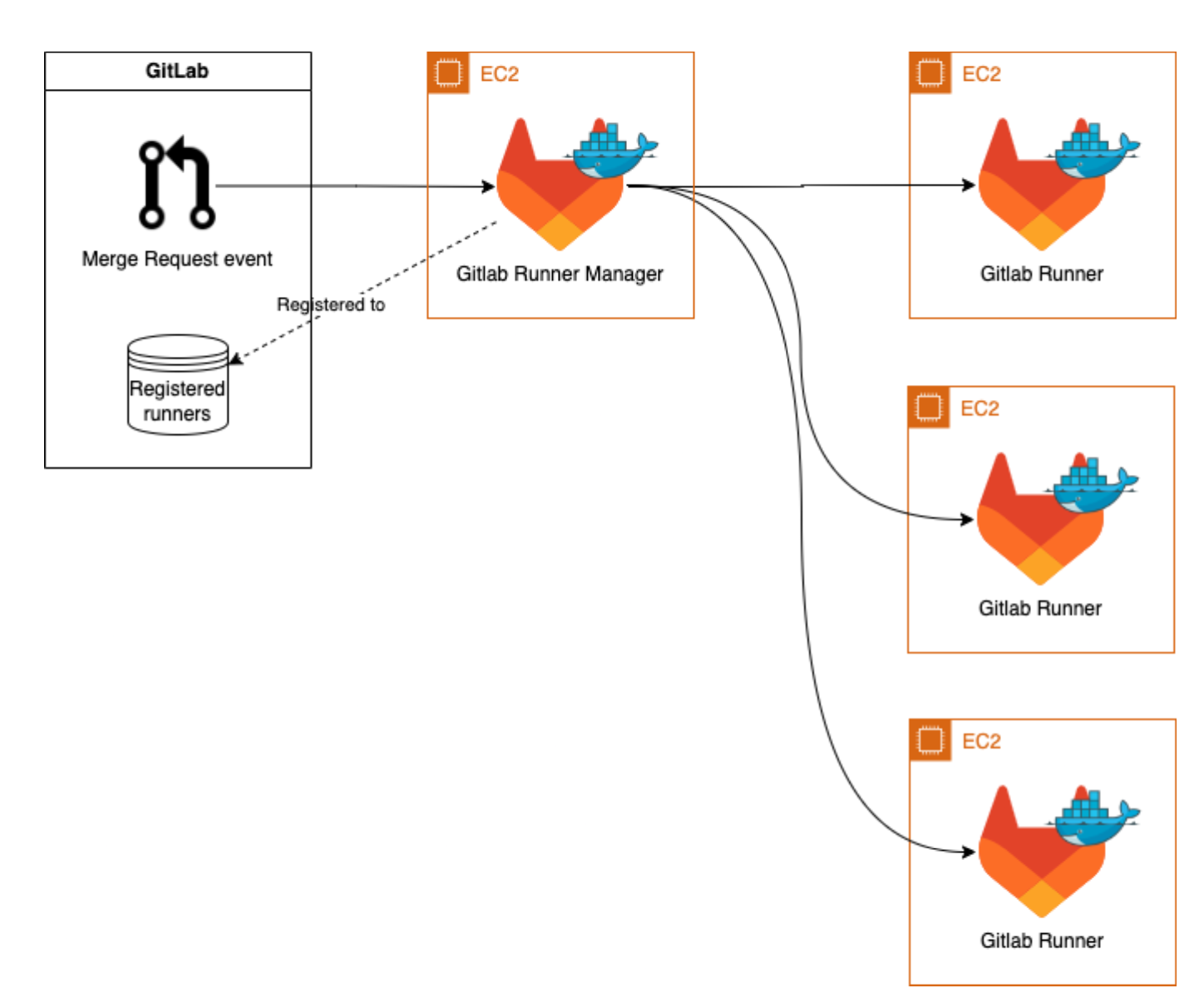
With this solution, only one runner is registered in GitLab and they manage the creation/termination of all other instances. Runners are created based on the current demand, so if there are 5 tasks in the queue, 5 machines are created to cover this need. One machine (GitLab runner manager) must be active 24/7, but in terms of performance it doesn’t have to be very powerful, as it only maintains the connection to the GitLab and manages the creation/termination of instances.
Such an auto-scaling solution is recommended directly by GitLab. This is mainly due to the simple setup and a non-stop running management machine, which can be operated quite cheaply. However, it also brings several disadvantages with it. For example, its support will end soon and one machine is able to solve only one task.
Docker-machine is very efficient in what it does. However, some tasks in the project require a different runtime environment than docker because they would run in it for too long. It was for this reason that we started to actively pursue approach number 2 at the beginning of the year.
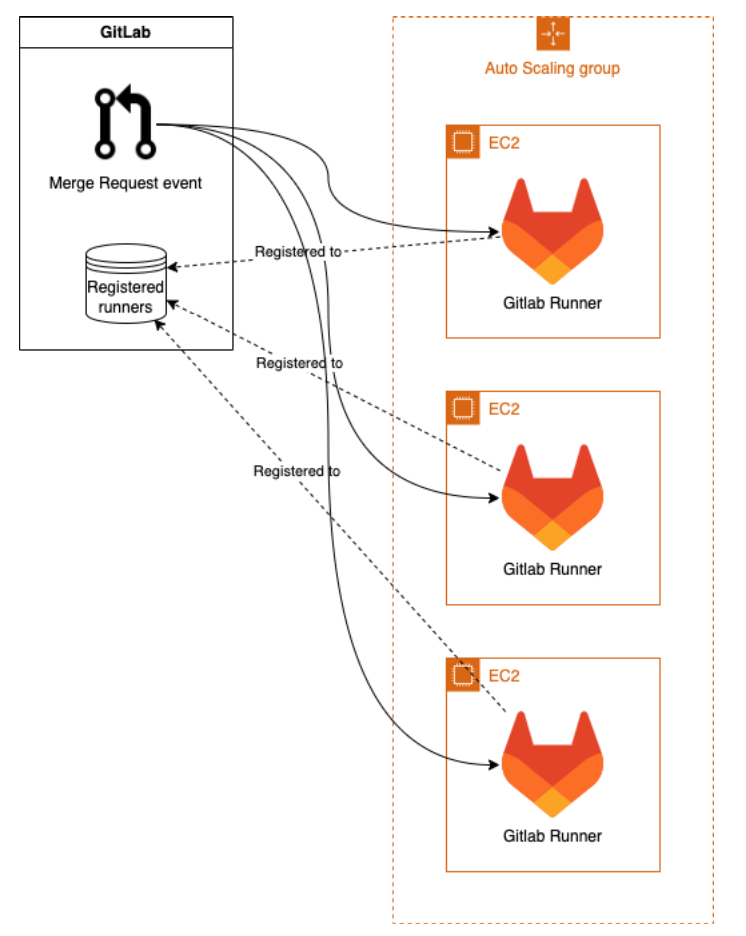
The Amazon Scale Group (ASG)
With this approach, each runner is registered in GitLab. Runners are created based on the current CPU usage in the entire group. If a certain limit value is reached, new machines are created. The disadvantage is that one full-fledged powerful machine must be active 24/7. At the same time, however, one machine can perform multiple tasks, and in addition, the use of resources can be efficiently managed using CloudFormation and CloudWatch.
Our breakpoints
Both services are provided by AWS precisely so that the user can efficiently automate the process of creating and managing infrastructure in the cloud. Using CloudFormation templates, it’s possible to define the required resources (such as EC2 instances, database instances, network components, storage, etc.) and their interrelationships.
CloudWatch, on the other hand, allows you to track and collect metrics, logs and events from various services within AWS. This allows you to set thresholds for certain processes as well as actions to be taken when these values are reached.
We have set two CloudWatch alarms that take into account the current CPU usage on all instances.
- If the usage exceeds 15 %, new machines are created.
- If the usage is below 5 %, the closure programme is triggered. The output of that program determines which instances can be terminated.
Which types of instances to choose?
The term “instance type” means a certain configuration of virtual instances – a combination of the number of CPUs and the amount of operating memory (RAM). Each type of instance (t3a, m5a, m5, t3 and many others) has its own specifications and price for every minute of their use. It’s therefore quite difficult to choose the one that will be best for the project. At Crossuite, we have prepaid time for m5 and t3a type machines as part of using Amazon services. As the easiest way to compare, I chose a simple test – I repeatedly ran a certain selected task with different configurations and made a comparison.
| Instance | CPU | RAM | Resulting time |
| m5.xlarge | 4 | 16 | 15m 51s |
| m5.2xlarge | 8 | 32 | 15m 7s |
| m5.8xlarge | 32 | 128 | 15m 16s |
| m5a.xlarge | 2 | 8 | >24m 4s |
| m5a.xlarge | 4 | 16 | 17m 17s |
| t3a.large | 2 | 8 | >94m 13s |
| t3a.xlarge | 4 | 16 | 18m 43s |
The most powerful, or at least the one with the most performance potential, is of course the m5.8xlarge, because it has the most CPU and RAM. However, as the test showed, its resulting time is approximately the same as that of the m5.xlarge. In this particular case, it turned out that tasks need at least 4 CPUs and at the same time can’t utilize more than 8GB of RAM. So we deployed m5a.xlarge, which provides us with a sufficient price-performance ratio. However, I’d like to point out that it’s smart to do such a test for each job separately, because it can always have different requirements and therefore a different ideal instance.
Overall, we’ve assessed ASG since its deployment in March 2023 as a positive step forward. It allowed us to auto-scale tasks that the docker-machine simply couldn’t solve. However, we still need to combine both approaches in order to achieve optimal results.



